Uploading files over the web is not an easy task. It involves considerable challenges in developing a solution that works for all file sizes. Uploading files are prone to failures, users drop, and security risks. On each failure, the file needs to be re-uploaded: which adversely affects associated user experience.
Problems
Network Bandwidth & File Size
The file upload takes considerable time: more the time to upload, more the chances of failures or connection drop. With each failure, a file needs to be re-uploaded from the beginning with traditional methods.
The time to upload file can be understood by the following equation:
time_to_upload = file_size / effective_bandwidth + overheadNote: The equation is oversimplified to explain relationships; it is not accurate; A variable is introduced for abstracting network overhead involved in the request.
It can be interpreted as:
- More the size ⇒ more time.
- Lesser the bandwidth ⇒ more time.
A large file on a slow network is the worst possible case.
Server Limitation
- Http servers restrict the size of a file that can be uploaded. The standard limit is
2GB. - The operating system or file journalling system also imposes a limit on the file size they can handle.
- Disk space availability also a factor that controls maximum file size that can be uploaded.
Security Risks
Uploading files is not free from Security Risks. The surface area of security risk depends upon the purpose of uploaded files.
- Denial of Service: Server spends most of the time serving a few requests; It expedites the hacking attempt in making Server go out of service.
- Code Infusion: File upload easily enables code to be uploaded if unchecked, and it may lead to system hijacking.
- File Overriding: Client provided path can trick Server into replacing any critical file.
Solution Idealization
The following idea or can be proposed to increase the user experience in uploading files:
- Pre Check: Pre checking with Server before uploading whether it can handle the request or not.
- Resumability: File upload should resumes if there is a failure in connecting. It can only if Server or Client stores the state of upload progress.
- Verification: File should be verified and scanned to eliminate any threat.
Solution Realization
The following are iterations of implementation options (Read in order); these may be feasible or not.
Pre-checking
Pre checking with Server is an additional network request; it may not be useful for small file size, but pre-checking for large files can be helpful.
With Http Header Expect: 100-continue¹
Http header Expect: 100-continue is a probing header that used to determine whether Server can receive the current request with large message body or not. If Server accepts, it sends back 100 else 417 status code. If Server accepts, a second request is trigged to upload the file.
The beauty of this mechanism is that the second request automatically trigged by Http Client. Unfortunately, It cannot be set via programming means available: fetch API or XHR (Ajax) request. It can only be set by an underlying user-agent or browser. Curl adds this header on crossing 1024KB request body size³; when browsers add this header, who knows ?
In short, A programming effort could not be made. Also, many Servers implementations do not understand this header.
It is a useful header to be practically useless. We need to pre-check through standard requests.
With Two Separate Standard HTTP requests
Overall uploading process can be conceptualized as two standard HTTP requests:
- A file metadata need to be sent first.
- Based upon the server response file can be uploaded.
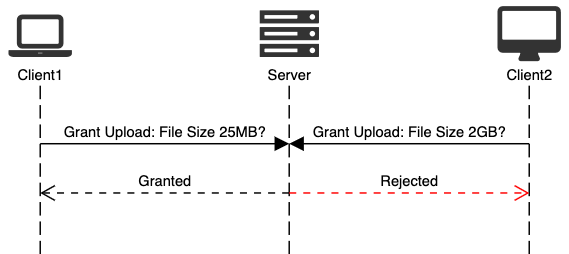
You need to develop a customised protocol of communication to realize this mechanism.
Without Reserving capacity
Let’s assume a situation server has 1GB space left. Imagine, two clients asking to upload at the same time:
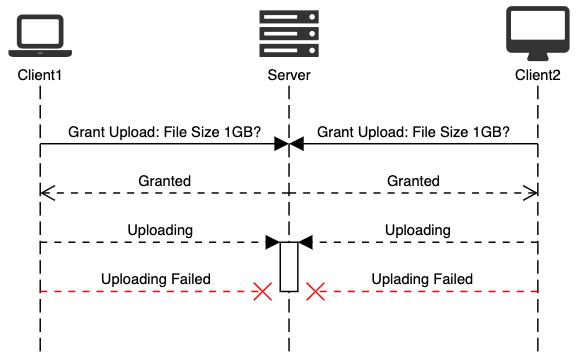
Both clients would get permission to upload, and after a while, both requests would be interrupted when Server gets 1 GB of combined data from both requests.
With Reserved Capacity
What if Server could reserve capacity for a file that is about to be uploaded?
It might look like a good idea, but it may not. A Server would be dealing with multiple requests at the moment, and not all of these would be successful. If unnoticed and unchecked, Server may run out of storage space soon; even though Server having enough storage space physically.
Also, any miscreant could learn it and can place an attack on service.
You need to carefully devise a strategy to reclaim space. If you are thinking of building resumability, Server needs to wait for some time to reclaim unused space.
With Dynamic Capacity
We live in a cloud computing world, where you don’t need to plan capacity (only if you have unlimited money 😌). Most of Cloud Providers provides Object Storage.
Object Storages obscure scalability challenges associated with traditional file systems, and provide a simplified API to access entity named Objects. An object is semantically equivalent to a file.
Modern databases too, include BLOB storage similar to Object Storage. Object Storages and Databases are similar in terms of file system abstraction, but Databases offer their operational challenges.
Resumability & Time
Chunking
When file size crosses a certain limit; it becomes necessary to split it and upload it in multiple requests.
A file is a sequence of bytes. We can collate some bytes into chunks. These chunks need to be individually uploaded by Client and combined by Server.
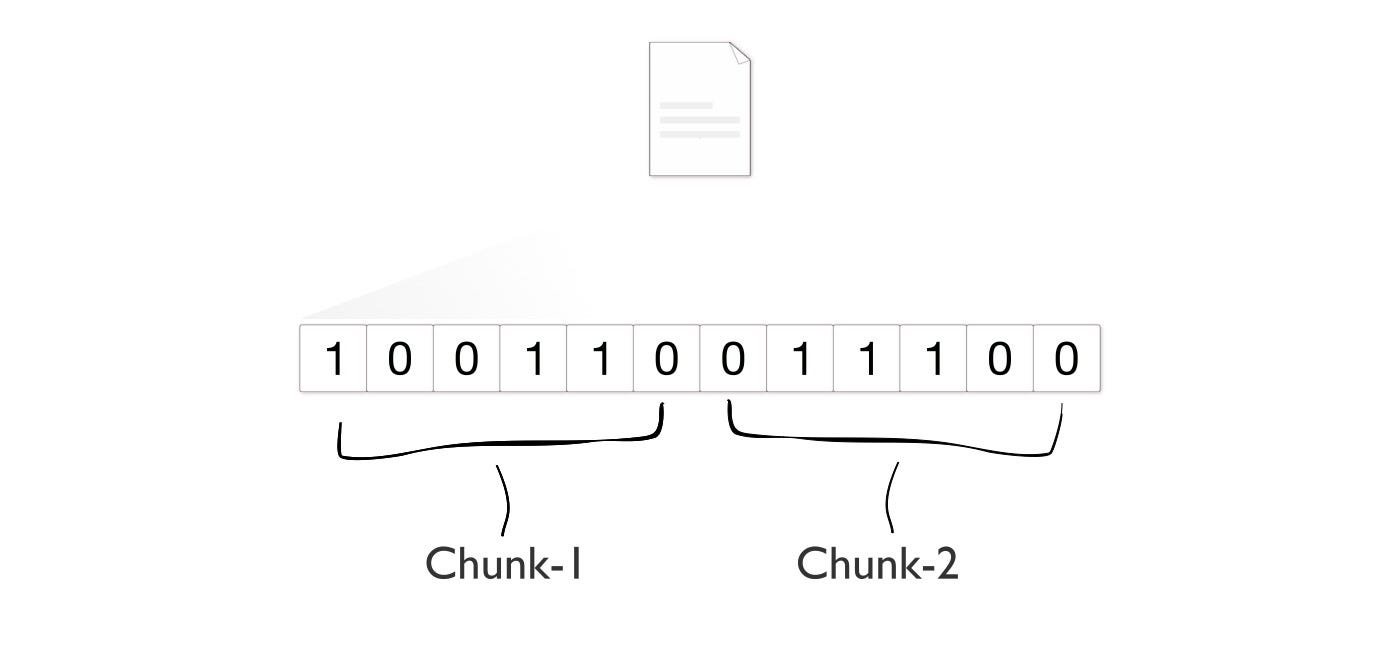
no_of_requests = file_size / chunk_size
time_to_a_request = chunk_size / bandwidth + overhead
time_to_upload ~ time_to_a_request * no_of_requestsIt is a bit slower than traditional mechanism as multiple requests increase networking overhead (ack), but it gives ultimate control in hand:
- Provide the ability to upload large files over
2GB. - Resumability can be build using this idea.
Chunking is effortful; it introduces additional metadata to be exchanged to build reliable file upload. HTML 5 provides many useful utilities to realize this mechanism.
Here is a basic code snippet to illustrate the core implementation of chunking:
// file is instance of File API
const file = form.querySelector('[input=file]').files[0]
const totalSize = file.size
// 10 KB : K = 1000 : Network transimission unit
const chunkSize = 10 * 1000
const noOfChunks = Math.ceil(totalSize / chunkSize)
let offset = 0
for (let i = 0; i < noOfChunks; i++) {
const chunk = file.slice(offset, offset + chunkSize)
// upload ajax request: hidden
offset = offset + chunkSize
}An article can be dedicated to design decisions associated with chunking; for now, you can explore Resumable.js and Tus before you mind up to build your implementation.
Compression
A file can be compressed before uploading to Server. Compression is a double edge sword as it may increase or decrease overall upload time.
total_to_upload = compression_time + upload_timeAlso, Server must understand the compression algorithm in place; it is part of content-negotiation strategies.
You must have proof of concept if you introduce compression.
Security
Scanning every uploaded file is an essential task. Additionally, you can consider the following security measurements:
Integrity Check
A transferred file must be validated. Checksum Checking is a well-known practice to verify file integrity. There are many hashing algorithms to choose from MD5, SHA-1, SHA-256, or many more. Whatever algorithm is chosen for whatsoever reasons, should be supported by both Client and Server implementation.
HTTP Header: Etag is used to exchange checksum. The calculated checksum value must be transferred over the secure channel (TLS).
Blacklisting
A file with executable permission can do more harm, especially if is application engine file like .php, .jsp, .js, .sh , and .asp.
Sandboxing or limited access is the key to protect the system.
At best, prevent users from uploading executable files.
Deep Content Disarm and Construction
Deep Content Disarm and Construction (Deep CDR) is a technique of rebuilding files from the file parts by discarding harmful components. It makes sense for files like pdf, doc or spreadsheet which allows embedded content. You can read about the technique in details here.
Closing Notes
The system attributes: kind of files, maximum allowed file size affect the implementation choices.
If you are storing files in a traditional file system, then limit the file size. It would require a considerable number of requests to place a DOS attack and hopefully detectable.
Devise a policy to define a time window to consider file upload failure and to eradicate partial-uploaded files.
With Chunking, it would seem like you are repeating implementation of TCP at higher granularity.
References
Expect Header
https://developer.mozilla.org/en-US/docs/Web/HTTP/Headers/ExpectWhen Curl sends 100 continue
https://gms.tf/when-curl-sends-100-continue.htmlFileSize Limitation
https://stackoverflow.com/q/5053290/3076874
FootNotes
Bandwidth is the amount of data that can be transferred in a unit of time.
Compression is information storage optimising encoding mechanism.